

Commençons par un rappel des 4 opérateurs avancés à connaître par cœur pour maîtriser ses recherches Google
site: va vous permettre de voir l’ensemble des pages du site ciblé indexées par Google (site:linkedin.com)
intitle: cherche un mot dans le titres de la page (intitle:cv)
Inurl: cherche un mot dans l’adresse URL (inurl:cv)
ext: cherche un format de fichier (ext:pdf)
Note : N’utilisez jamais de majuscule ni d’espace avec les opérateurs avancés. En effet si vous tapez intitle: cv Google va chercher le mot intitle ET le mot CV (espace = ET).
Les deux opérateurs intitle: et inurl: vont chercher le mot exact et prennent en compte les accents
Savoir cela c’est bien mais cela ne suffit pas pour faire des requêtes efficaces. Encore faut-il savoir comment et dans quels cas les utiliser.
Avant d’effectuer une recherche de Google, posez-vous une première question : « est-ce que je sais où trouver les candidats qui m’intéressent ? » A cette question, deux réponses possibles et deux comportements différents à adopter.
Lorsque la réponse à cette question est OUI, je sais que sur Linkedin, Dribble, Github, Datasciencecentrale, etc. je vais pouvoir trouver ce que je cherche (en l’occurrence des profils). Dans ce cas-là vous allez utiliser Google comme le moteur de recherche avancé du site que vous voulez cibler. Et pour ce faire, vous devez étudier la structure du site parce que chaque requête est unique et doit être construite en fonction de l’organisation de celui-ci.
La méthode à appliquer est la suivante :
1. Je repère l’information qui m’intéresse
2. J’observe l’URL de la page
3. J’observe le titre de la page
4. Je repère s’il existe des champs textes structurés que je vais pouvoir transformer en critères de recherche
Prenons l’exemple de Linkedin et analysons la structure d’un profil :
1. et 2. Je repère l’information qui m’intéresse et j’observe l’URL de la page
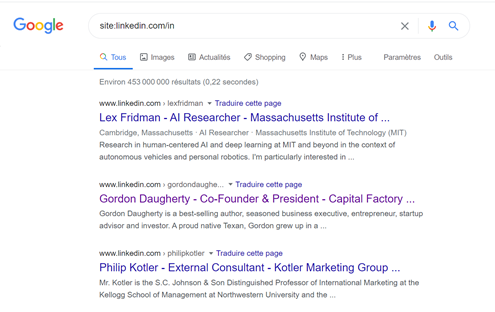
Chaque page Internet est rangée dans un répertoire et -en règle générale- les informations similaires seront rangées dans un répertoire commun. Ainsi dans l’exemple ci-dessus le profil est rangé dans un répertoire qui s’appelle « in ». Si vous avez un doute, allez voir plusieurs profils et vérifiez que « in » est bien le répertoire qui héberge les profils.
Vous allez alors scanner le site (X-Ray search) jusqu’au répertoire qui vous intéresse en utilisant l’opérateur site: et accéder ainsi à l’ensemble des profils Linkedin (pas tout à fait l’ensemble des profils car ceux qui ont désindexé leur profil public de Google ne seront pas visibles)
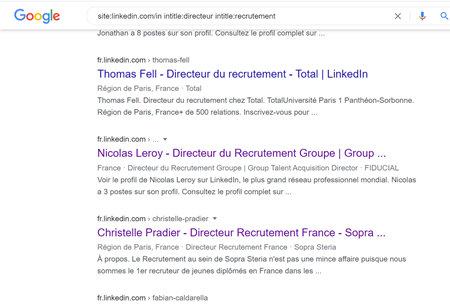
3. J’observe les titres des pages
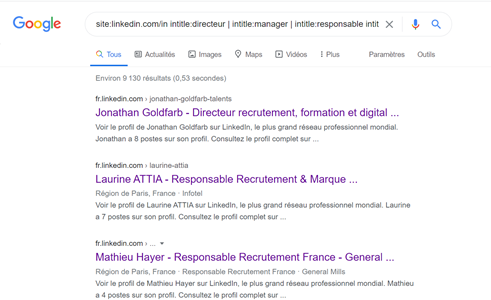
Les titres de pages apparaissent en bleu dans les résultats Google. Que remarquons-nous ? Les titres reprennent automatiquement le prénom, le nom du profil ainsi que le poste actuel et l’entreprise actuelle. Autant d’information que je peux transformer en critères de recherche en utilisant l’opérateur intitle: Ainsi la formule site:linkedin.com/in intitle:directeur intitle:recrutement me donnera la liste des profils Linkedin dont le poste actuel est directeur du recrutement.
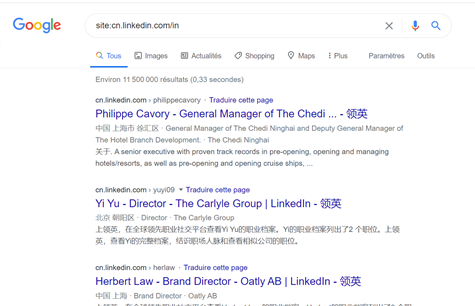
Note : à cette étape, observez les URL des profils. Un code pays est indiqué devant le site (fr.linkedin.com). Vous pouvez donc utiliser ce critère pour modifier la provenance des profils.Par exemple, je peux faire une recherche sur les profils Linkedin basés en Chine ou dans n’importe quel autre pays.
Mais revenons à notre requête site:linkedin.com/in intitle:directeur intitle:recrutement
Je peux évidemment ajouter des synonymes à chaque mot clé. Par exemple si je cherche des directeurs ou responsables ou manager recrutement…
site:linkedin.com/in intitle:directeur | intitle:manager | intitle:responsable intitle:recrutement
A cette étape, je formaliserai ainsi la structure des profils Linkedin :
URL = pays.linkedin.com/in
TITRE = prénom + nom + poste actuel + entreprise actuelle
Reste le critère qui pose généralement le plus de problèmes aux sourceurs, à savoir la localisation. Celle-ci n’étant indiquée ni dans les URL, ni dans les titres de pages, nous allons étudier si elle apparaît dans un champ texte structuré.
4. Je repère s’il existe des champs textes structurés que je vais pouvoir transformer en critères de recherche
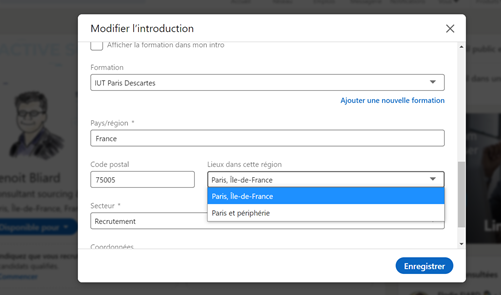
Qu’est-ce qu’un champ texte structuré ? Il s’agit d’une information qui s’exprime toujours avec la même structure. Une des façons de repérer un champ texte structuré est d’aller sur son propre profil et de cliquer sur l’icône représentant un crayon (en haut à gauche) qui va me permettre de modifier mes informations.
En indiquant le code postal qui me correspond, Linkedin me propose deux structures différentes :
« ville region » ou « ville et peripherie »
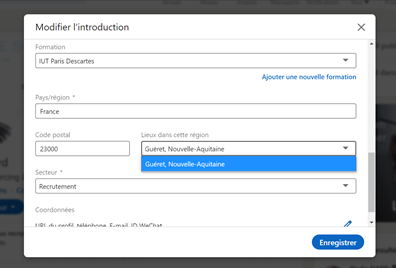
Attention si vous recherchez un candidat dans une zone géographique peu peuplée, la structure « ville et péripherie » n’existe pas. Par exemple, si je cherche un profil dans la Creuse (je sais… j’ai choisi un exemple extrême) et que vous tapez 23000 dans le champ code postal, Linkedin vous propose uniquement « Gueret Nouvelle Aquitaine »
Donc si on finalise l’analyse de la structure des profils Linkedin :
URL = pays.linkedin.com/in
TITRE = prénom + nom + poste actuel + entreprise actuelle
CHAMPS TEXTES STRUCTURES = « ville et peripherie » ou « ville region »
Pour résume si je cherche à identifier les patrons du recrutement sur Linkedin en IDF, je peux taper
site:linkedin.com/in intitle:directeur | intitle:responsable | intitle:manager intitle:recrutement « paris et peripherie »
Bien sûr je dois aussi envisager que le profil peut s’appeler talent acquisition, recruiter, head of talent, etc.
L’analyse de la structure d’un site n’est pas toujours aussi simple. Il arrive que l’information recherchée ne soit dans aucun répertoire (par exemple sur Github) ou que le répertoire qui nous intéresse se trouve après un répertoire aléatoire (par exemple sur Dogfinance).
Dans le premier cas de figure (il n’existe pas de répertoire spécifique) vous devez raisonner à l’envers : puisque vous ne pouvez pas chercher spécifiquement l’information qui vous intéresse, vous devez exclure toutes les pages qui ne vous intéressent pas. Soit en supprimant les répertoires qui polluent vos résultats (-inurl:), soit en supprimant dans les titres les éléments communs à ce que vous souhaitez exclure (-intitle:)
Dans le deuxième cas de figure (le répertoire qui vous intéresse se trouve après un répertoire aléatoire vous pouvez utiliser l’astérisque (*). Dans l’exemple ci-dessous le répertoire qui m’intéresse s’appelle p mais il se trouve derrière un répertoire langue (fr).
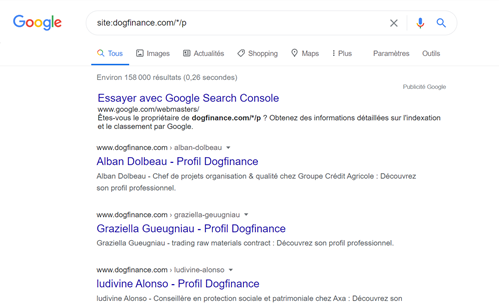
Si j’utilise la formule site :dogfinance.com/*/p je dis à Google : « je veux voir toutes les pages de Dogfinance.com qui sont dans le répertoire p quel que soit la langue de paramétrage
site:dogfinance.com/fr/p montre les profils qui ont paramétré leur page en français
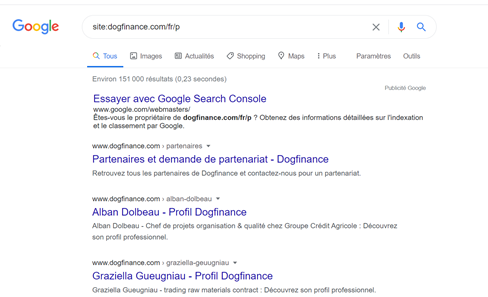
site:dogfinance.com/en/p montre les profils qui ont paramétré leur page en anglais
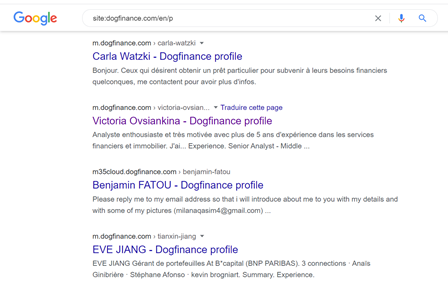
site:dogfinance.com/*/p montre les profils quel que soit la langue de paramétrage de la page
Pour résumer, le meilleur conseil que l’on puisse donner à un sourceur qui souhaite utiliser les techniques de X-Ray search (site:) est d’OBSERVER le site cible :
-quel est le répertoire ?
-quelle informations dans les titres de page ?
-y-a-t-il des champs textes structurés ?
Et puis parfois, nous ne savons pas où trouver l’information… il n’y a donc rien à observer puisque nous allons chercher l’information parmi les milliards de pages de Google.
Cela fera l’objet du prochain article 😊

Benoit Bliard accompagne les professionnels du recrutement depuis plus de 20 ans.
Depuis 2010, il travaille sur les problématiques de sourcing de CV via le Web. Expert Google Search, il développe un programme de formation dédié au techniques de recherche via Google et forme depuis 2011 les recruteurs à identifier CV et compétences par ce biais.